Project: Analyzing San Francisco Salaries Data
In this project, we will analyze San Francisco employee’s salaries data that is available on Kaggle. We will learn:
- Data exploration using Pandas
- Converting object columns to numeric
- Finding null values
- Imputing null values using both fillna method and SimpleImputer
#Imports
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
#Import data from the csv file
salaries = pd.read_csv('Salaries.csv')
#Glimpse of data
salaries.head()
| Id | EmployeeName | JobTitle | BasePay | OvertimePay | OtherPay | Benefits | TotalPay | TotalPayBenefits | Year | Notes | Agency | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | NATHANIEL FORD | GENERAL MANAGER-METROPOLITAN TRANSIT AUTHORITY | 167411 | 0 | 400184 | NaN | 567595.43 | 567595.43 | 2011 | NaN | San Francisco | NaN |
| 1 | 2 | GARY JIMENEZ | CAPTAIN III (POLICE DEPARTMENT) | 155966 | 245132 | 137811 | NaN | 538909.28 | 538909.28 | 2011 | NaN | San Francisco | NaN |
| 2 | 3 | ALBERT PARDINI | CAPTAIN III (POLICE DEPARTMENT) | 212739 | 106088 | 16452.6 | NaN | 335279.91 | 335279.91 | 2011 | NaN | San Francisco | NaN |
| 3 | 4 | CHRISTOPHER CHONG | WIRE ROPE CABLE MAINTENANCE MECHANIC | 77916 | 56120.7 | 198307 | NaN | 332343.61 | 332343.61 | 2011 | NaN | San Francisco | NaN |
| 4 | 5 | PATRICK GARDNER | DEPUTY CHIEF OF DEPARTMENT,(FIRE DEPARTMENT) | 134402 | 9737 | 182235 | NaN | 326373.19 | 326373.19 | 2011 | NaN | San Francisco | NaN |
#Data information
salaries.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 148654 entries, 0 to 148653
Data columns (total 13 columns):
Id 148654 non-null int64
EmployeeName 148654 non-null object
JobTitle 148654 non-null object
BasePay 148049 non-null object
OvertimePay 148654 non-null object
OtherPay 148654 non-null object
Benefits 112495 non-null object
TotalPay 148654 non-null float64
TotalPayBenefits 148654 non-null float64
Year 148654 non-null int64
Notes 0 non-null float64
Agency 148654 non-null object
Status 38119 non-null object
dtypes: float64(3), int64(2), object(8)
memory usage: 14.7+ MB
#Before we start analyzing the data. Lets see if we have any null values anywhere. We might have to take care of them first.
plt.figure(figsize=(10,6))
sns.heatmap(salaries.isnull(),cmap='viridis',yticklabels=False,cbar=False)
<matplotlib.axes._subplots.AxesSubplot at 0x242869b5b00>
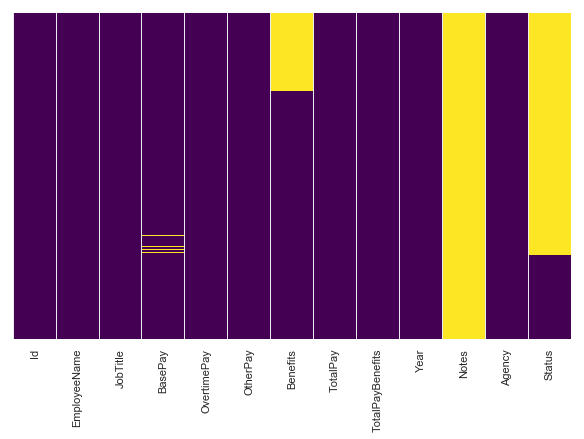
#Find the columns where null value exists and then count the null values
{col:salaries[col].isnull().sum() for col in salaries.columns if salaries[col].isnull().any()}
{'BasePay': 605, 'Benefits': 36159, 'Notes': 148654, 'Status': 110535}
Looks like we have to drop the Notes and Status column as there are alot of null values.
salaries.drop(['Notes','Status'],axis=1,inplace=True)
Let’s now focus on the BasePay and Benefits column. We will convert both the columns to ‘float64’ type. However, both the columns contain ‘Not Provided’ value which we will convert to nan so that it will be treated with other nan values.
salaries['BasePay'][salaries['BasePay']=='Not Provided'] = np.nan
salaries['BasePay'] = pd.to_numeric(salaries['BasePay'])
salaries['BasePay'].dtype
dtype('float64')
Let’s repeat the same for ‘Benefits’ column.
salaries['Benefits'][salaries['Benefits']=='Not Provided'] = np.nan
salaries['Benefits'] = pd.to_numeric(salaries['Benefits'])
salaries['BasePay'].dtype
dtype('float64')
Now that both the columns are numeric, we can take care of the null values.
salaries['Benefits'].fillna(value=0,inplace=True)
We will fill the null values of BasePay column with the mean of that column. However, i want to show you another method of taking care of null values i.e. SimpleImputer
from sklearn.impute import SimpleImputer
si = SimpleImputer(strategy='mean')
salaries['BasePay'] = pd.DataFrame(si.fit_transform(np.array(salaries['BasePay']).reshape(-1,1)))
#Lets check if we have any null values in BasePay column now
salaries['BasePay'].isnull().any()
False
Now that we have taken care of the null values, lets explore the data.
#Avg BasePay
salaries['BasePay'].mean()
66325.44884050524
#Job title of DAVID FRANKLIN
salaries[salaries['EmployeeName'] == 'DAVID FRANKLIN']['JobTitle']
14 BATTALION CHIEF, (FIRE DEPARTMENT)
Name: JobTitle, dtype: object
#How much does DAVID FRANKLIN make
salaries[salaries['EmployeeName'] == 'DAVID FRANKLIN']['TotalPayBenefits']
14 286347.05
Name: TotalPayBenefits, dtype: float64
#Name of highest paid person
salaries[salaries['TotalPayBenefits']==salaries['TotalPayBenefits'].max()]['EmployeeName']
0 NATHANIEL FORD
Name: EmployeeName, dtype: object
#Name and pay of lowest paid person
salaries[salaries['TotalPayBenefits']==salaries['TotalPayBenefits'].min()][['EmployeeName','TotalPayBenefits']]
| EmployeeName | TotalPayBenefits | |
|---|---|---|
| 148653 | Joe Lopez | -618.13 |
#Avg BasePay of all employees per year from 2011-2014
salaries.groupby(by='Year').mean()['BasePay']
Year
2011 63595.956517
2012 65436.406857
2013 69576.866579
2014 66564.396851
Name: BasePay, dtype: float64
#Number of Unique job titles
salaries['JobTitle'].nunique()
2159
#Top 5 most common jobs
salaries['JobTitle'].value_counts().head()
Transit Operator 7036
Special Nurse 4389
Registered Nurse 3736
Public Svc Aide-Public Works 2518
Police Officer 3 2421
Name: JobTitle, dtype: int64
#Number of Job titles with only one occurence in 2013
sum(salaries[salaries['Year']==2013]['JobTitle'].value_counts()==1)
202
#To view those 202 Job titles
salaries.groupby(by=['Year','JobTitle']).count().loc[2013,'Id'][salaries.groupby(by=['Year','JobTitle']).count().loc[2013,'Id']==1]
JobTitle
Acupuncturist 1
Adm, SFGH Medical Center 1
Administrative Analyst I 1
Administrative Analyst II 1
Administrator, DPH 1
Airport Communications Officer 1
Airport Mechanical Maint Sprv 1
Animal Care Asst Supv 1
Animal Care Supervisor 1
Animal Control Supervisor 1
Arborist Technician Supv II 1
Area Sprv Parks, Squares & Fac 1
Asphalt Plant Supervisor 1 1
Assessor 1
Assistant Director, Probate 1
Assistant Industrial Hygienist 1
Assistant Inspector 1
Assistant Inspector 2 1
Assistant Law Librarian 1
Assistant Power House Operator 1
Assistant Sheriff 1
Assoc Musm Cnsrvt, AAM 1
Asst Chf, Bur Clm Invest&Admin 1
Asst Dir of Clinical Svcs 1 1
Asst Dir, Log Cabin Rnch 1
Asst Director, Juvenile Hall 1
Asst Superintendent Rec 1
Attorney, Tax Collector 1
Auto Body & Fender Wrk Sprv 1 1
Baker 1
..
Special Assistant 21 1
Specialist in Aging 2 1
Sprv Adult Prob Ofc (SFERS) 1
Sr Employee Asst Counselor 1
Sr General Utility Mechanic 1
Sr Light Rail Veh Equip Eng 1
Sr Medical Transcriber Typist 1
Sr Opers Mgr 1
Statistician 1
Sup Ct Admin Secretary 1
Sup Welfare Fraud Investigator 1
Supervising Parts Storekeeper 1
Supply Room Attendant 1
Telecommunications Tech Supv 1
Track Maint Supt, Muni Railway 1
Traf Signal Electrician Sup II 1
Traffic Sign Manager 1
Traffic Signal Operator 1
Training Coordinator 1
Training Technician 1
Transit Paint Shop Sprv1 1
Treasurer 1
Trnst Power Line Wrk Sprv 2 1
Undersheriff 1
Vet Laboratory Technologist 1
Victim & Witness Technician 1
Water Meter Shop Supervisor 1 1
Wharfinger 1 1
Window Cleaner Supervisor 1
Wire Rope Cable Maint Sprv 1
Name: Id, Length: 202, dtype: int64
#How many people have the word Chief in their job title
len(salaries[salaries['JobTitle'].apply(lambda x:'chief' in x.lower())])
627
#Is there a relation between length of Jobtitle and Salary
salaries['title_length'] = salaries['JobTitle'].apply(len)
salaries[['title_length','TotalPayBenefits']].corr()
| title_length | TotalPayBenefits | |
|---|---|---|
| title_length | 1.000000 | -0.036878 |
| TotalPayBenefits | -0.036878 | 1.000000 |
Seems there is no correlation between the two variables.
Leave a comment